The current version of the iOS application allows you to:
- Scan ISBN numbers for book details
- Scan University Library barcodes for book and thesis details
- Enter DOI numbers for papers and articles
- Extract the title of a website
- Manually add the details of books, papers and thesis
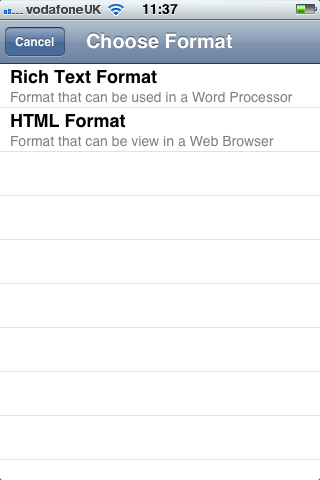
- Export the references via email to Rich Text Format (RTF) or HTML
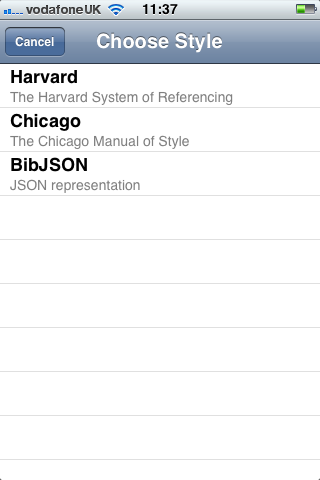
- Support for the Chicago and Harvard reference styles
The application only supports those devices that have a camera that can auto-focus (iPhone 3GS, 4 and 4S and the iPad 3). We need a camera that can autofocus for barcode reading. It would be possible to have the application check the capabilities of the device and only have the ‘scan’ option appear if you have an appropriate device.
This rest of this post provides a tour of the user interface and the functionality of the application.
The Main Screen
The main screen of the application shows a scrollable list of captured references:

By default the references are displayed in the Harvard style, but it is possible to switch to the Chicago style:

You can edit the details of captured references or delete them completely:
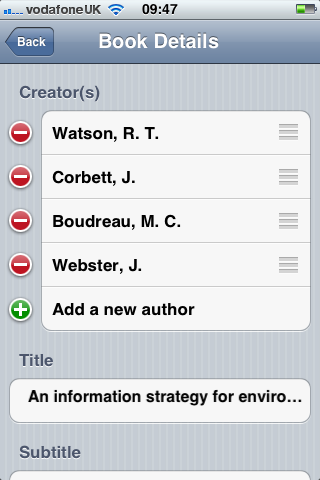

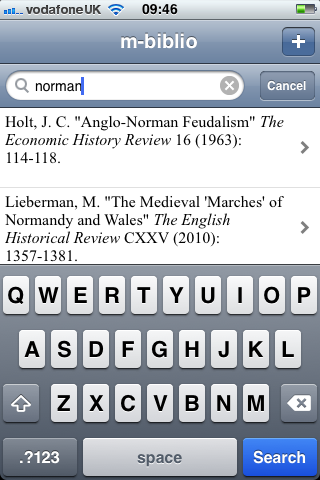
If you have captured a large number of references you can search by keywords (author or title):
Adding a Reference
The ‘Add’ icon on the top right of the main screen shows a new screen that allows you to add new references:
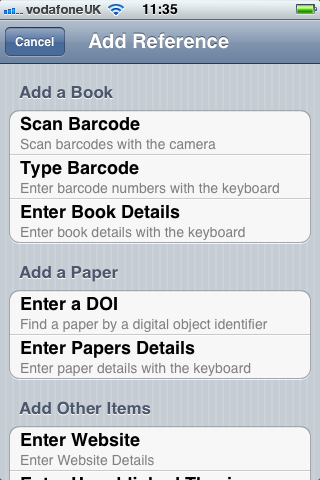
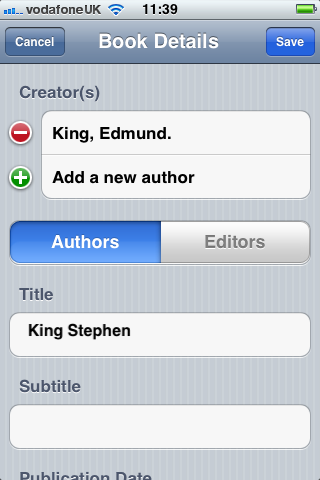
For example, we can scan a University Library barcode or an ISBN barcode with the camera on the phone:

After a successful scan, the app will query the m-biblio service for bibliographic data:

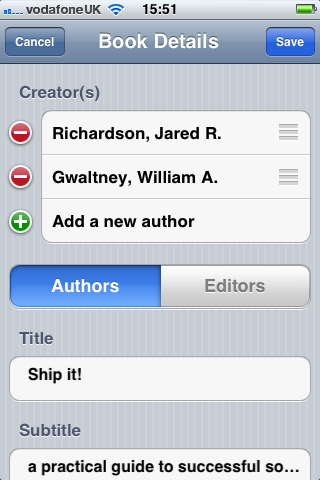
The end user can then modify the data (if they wish) before saving:
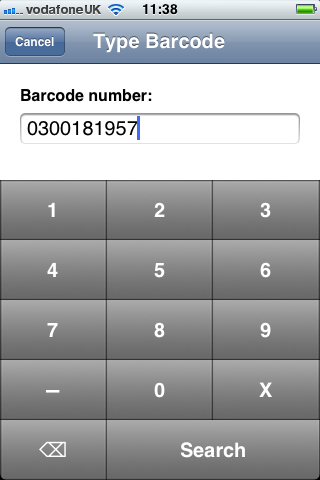
You can also type in a barcode number with a custom keyboard:
For Digital Object Identifiers (DOIs) you can type in the reference:
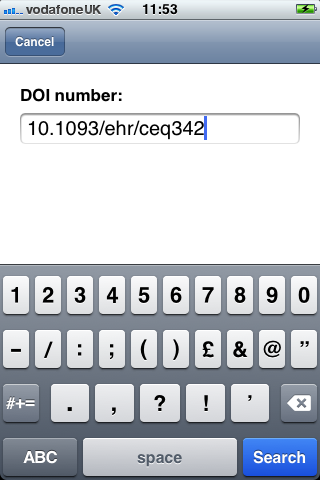
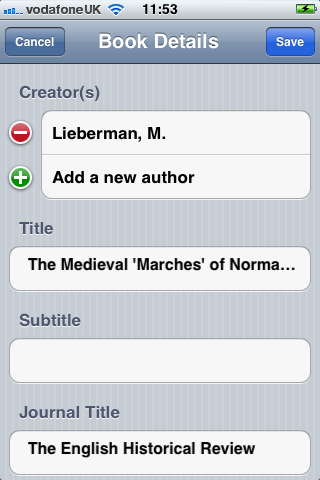
It would be better, in a future version of the app, if the DOI could be scanned in using some Optical character recognition (OCR) technique. The DOI numbers can be long and have a mix of numbers and characters which are prone to error when submitting on the iOS keyboard. For example, the DOI for J.C. Holt’s article on ‘Anglo-Norman Feudalism’ is ‘10.1111/j.1468-0289.1963.tb01721.x’.
You can also extract information about a website:

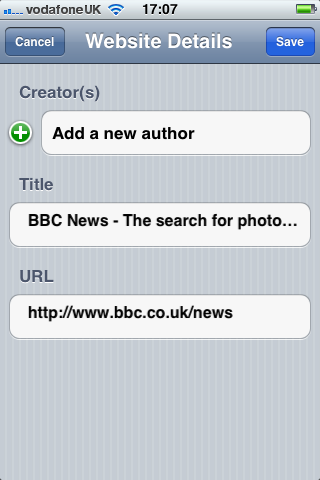
At the moment, you can only extract the title of a website. In the future, it would be nice to extract data from meta tags if they are relevant, such as details of authorship.
Exporting the references
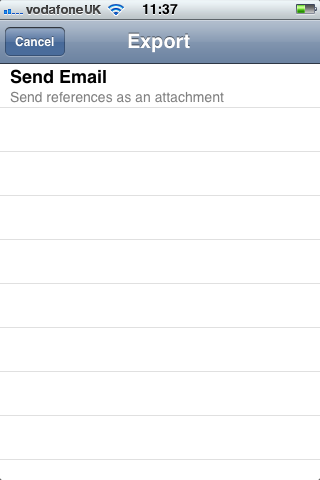
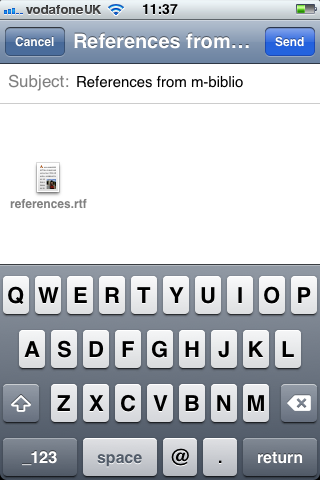
On the main screen the “Share” button allows you to export the references that you have captured. You can only export data via an email attachment (although there is code to support BibServer). You choose a format (Harvard or Chicago) and whether or not you want an RTF file or HTML:
Preferences
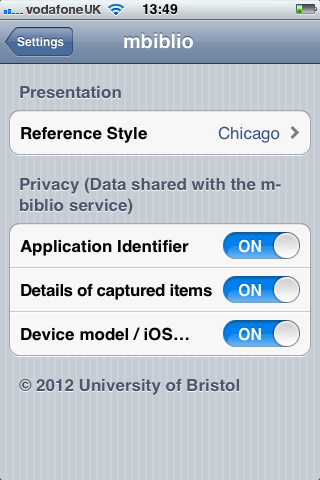
The preferences for the panel allows you to choose which reference style should be used for displaying references within the application. It also allows you to determine what information you are willing to share with the m-biblio service: (1) a unique identifier for the app; (2) the details of the captured items, i.e. the barcode or DOI number; (3) the type of device you are using (iPhone, iPad etc.) and which version of the operating system.
What’s missing
The is missing a number of things:
- The ability to manage references within collections. For example, you might have a collection for each assignment or task.
- Support for Endnote – it is vital that you can export your references to existing bibliographical material.
- More citation styles need to be supported and the ability to tweak the ones that are supported. For example, how many authors should be listed before et alias is used.
- We support books, but not chapters within books.