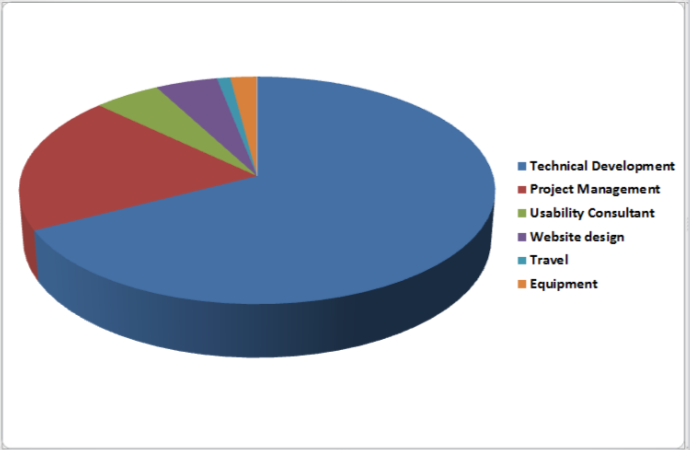
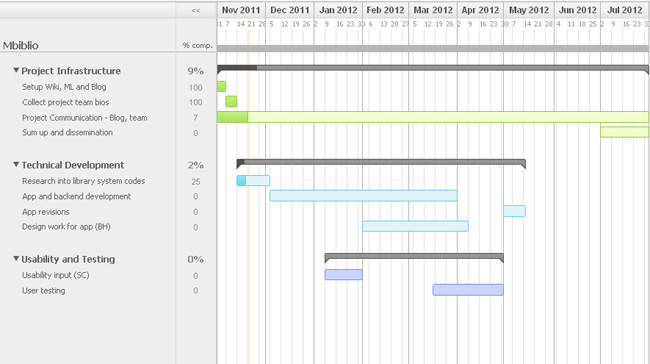
The M-Biblio project recently ran a workshop with 10 students representing a good cross-section of the student population at Bristol. The object of the workshop was twofold. Firstly, to obtain a better picture of the challenges students typically face when collecting and organising bibliographic references and secondly, to explore potential solutions and scenarios to inform work on the phone app.
Pain points
Overall the students gave the impression that collecting and organising bibliographic references was a less than enjoyable experience. It was described as a “messy” affair complicated by a lack of uniformity with regard to presentational expectations. Different lecturers within the same departments often have different requirements as to how references are presented. This lack of consistency in presentational standards is further exacerbated by the plethora of collection and organisational methods being utilised, ranging from handwritten notes to using dedicated packages such as Endnote. Where software was utilised there was the repeatedly flagged up issue of it not working as the students expected, or desired. And with applications such as Endnote, considerable time is needed in order to learn how to use the application efficiently – time students were reluctant to dedicate to something viewed as being peripheral to their central studies.
Mission Impossible
After assessing the status quo the workshop moved on to phase 2 which encouraged the attendees to design their own ideal reference collection and management solution based around a mobile phone. The only constraint was that they had to utilise real features currently available on smart phones.
Some of the ideas that emerged during this stage of the workshop were the ability to:
- add references from Google Scholar/Web of Science et al
- easily extract references from PDFs! (i.e. allowing copy & paste, rather than being restricted by locked files)
- Manually add references
- photograph book cover, with app automatically recognizing book and pulling in reference
- scan barcodes
- scan text information inside front cover (eg ISBN)
- OCR text (for references or notes)
- order collected references (alphabetical, by first author is most wanted, but maybe numerically sometimes)
- filter and winnow references (will collect more than needed to start with, some will be rejected for the actual essay)
- link or check references are cited within the essay or report
- format references according to common formats, such as Harvard. Freedom to define custom formats is very important too (to meet whims of lecturers!)
- export reference list to text/pdf/word formats
- share list via email/text/store in cloud
- produce sensible layout for URIs for web resources (incl correct layout and date viewed)
- be smart (e.g. identify Smith 2007 as a citation in the essay text and suggest possible references)
- automatically translate text in documents (like Google Goggles?)
- manage reference lists