Major Outputs
The m-biblio project has produced a number of significant outputs:
- Results of a survey with students
- Report on workshop with students
- Software for finding, storing and exporting references:
- A java-based web service for querying third-party bibliographic sources.
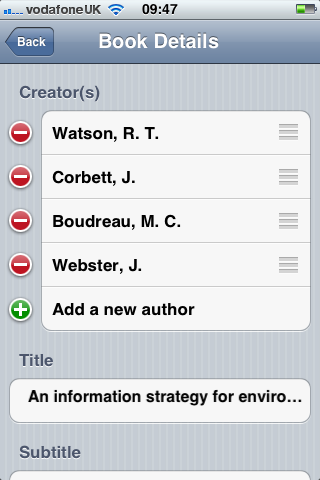
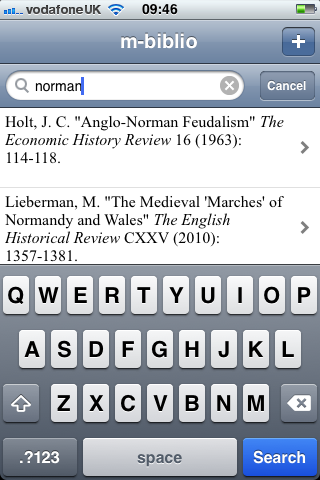
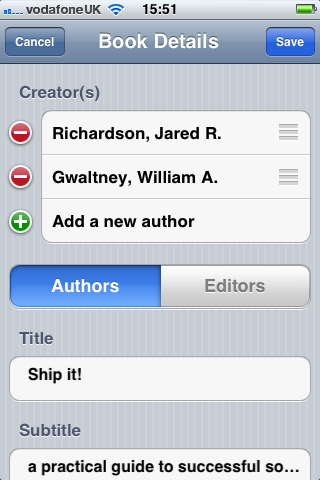
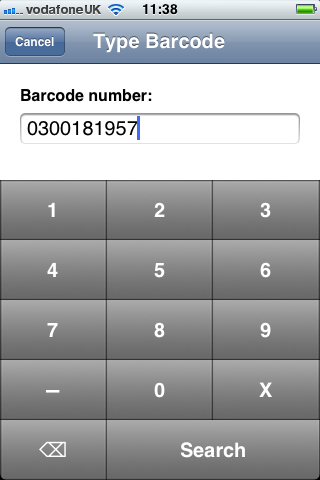
- An iOS application that uses the camera to scan barcodes band manage citations.
Background
The m-biblio project was managed by the R&D/ILRT team of IT Services at the University of Bristol. The University, founded in 1876, is internationally distinguished as one of the best universities in the UK with world-class research and excellent teaching.
The m-biblio project wanted to look at the potential for smart phones to be used for the recording and organisation of bibliographic information for students within a library context.
The initial proposal stated:
“We propose to enhance the learning and research activities of the University of Bristol’s academic community by developing a mobile application that can record and organise references to books, journals and other resources. These references can be added actively by scanning barcodes and QR codes, or passively by automatically recording RFID tags in items being used for study and research. With permission of the user, the application will submit anonymous usage data to their library. This innovation will provide library staff with a valuable set of user-derived usage statistics. It will be able to track which resources were used, and where. The library will therefore be given a rich seam of usage patterns, including data about library items that are often confined to branches such as periodicals, journals and reference books. The application will be made available to the wider FE/HE community for use in other institutions.”
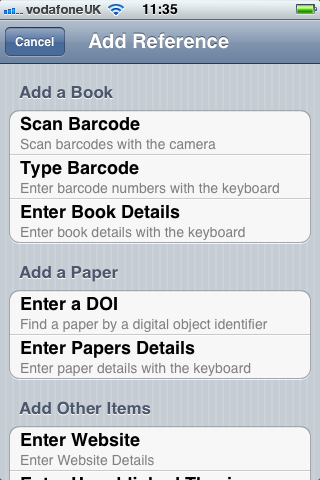
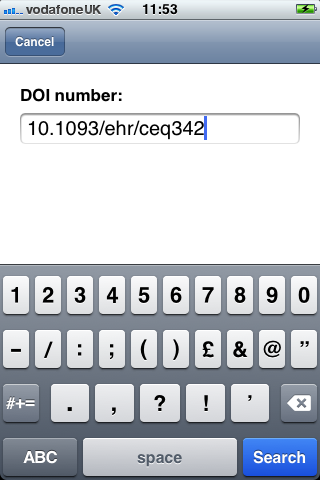
The project focussed on barcodes for books and Digital Object Identifers (DOIs) for papers and journals. The Library at the University of Bristol doesn’t use QR codes within the catalogue and it became apparent that we couldn’t read our RFID tags with an NFC capable device. However, we were successful in meeting a number of objectives, including investigation the student workflow and creating a prototype.
The challenge
Smartphone ownership among students is on the increase and the devices are bundled with a number of sensors such as cameras and, more recently, NFC readers. We wanted to investigate how we could use the phones to help students more accurately capture and manage references. A number of existing applications exist for managing references, such as Endnote, and we wanted to provide a tool that would work within a students existing study or research workflow which might already use such tools.
The Mobile Advantage
The prototype application does demonstrate the possibilities of using mobile devices to help collect and manage references. Work with students demonstrated that they had problems capturing the details of items accurately and displaying them in the correct format. In addition, a large percentage of students didn’t take advantage of bibliographic management tools. There is a gap in the market to provide a simple phone-based tool that can capture references.
Lessons Learnt
There were a number of key points:
- The capturing and management of references is a particular stress point for students. They can find it difficult to capture accurate references and provide them in the format expected by their tutors.
- Some students find existing bibliographic tools overly complex to use.
- It is possible to provide a tool that can improve the capture and accuracy of references. However, references might need amending due to errors or missing information when they were originally catalogued.
- There are copyright issues relating to the data provided by publishers that needs to be considered when deploying an app within an institution.
Technical Approach
There were two key pieces of technology developed for the project:
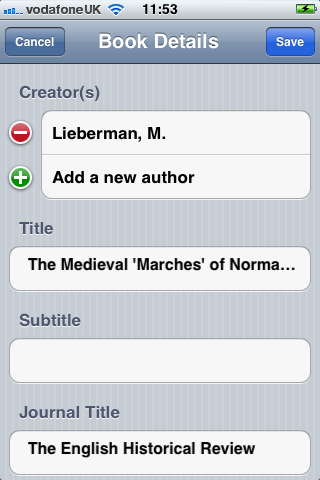
First, a Java web service (JAX-RS) that took a unique identifier (barcode, DOI number) and then queried a third-party bibliographic service for matching results. The results were then returned to the querying client in the JSON format. For University barcodes, the institution’s library catalogue (Aleph) was queried. COPAC was used for ISBN numbers and Crossref was used for DOI numbers.
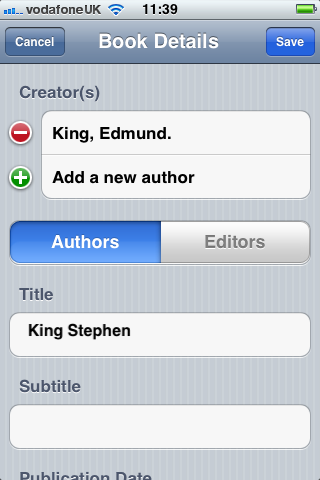
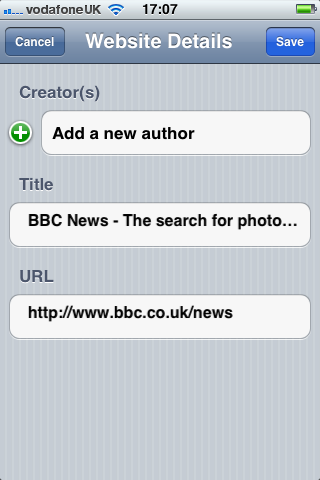
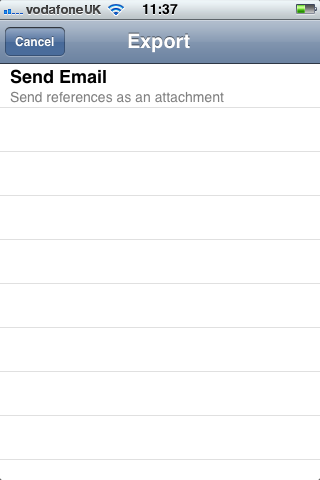
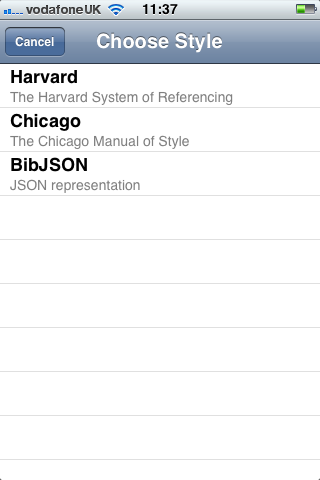
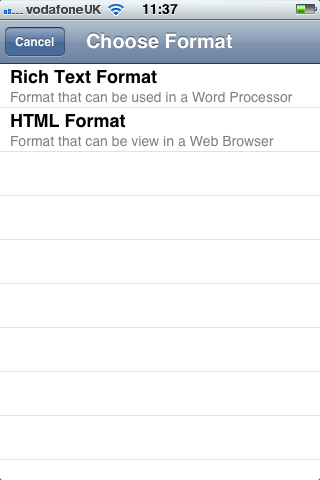
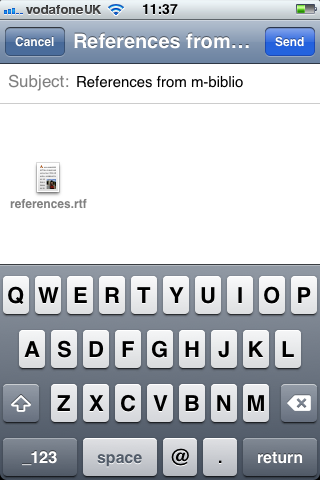
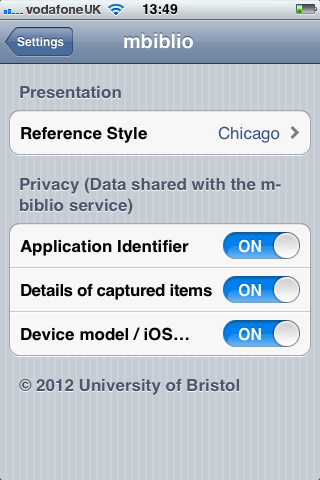
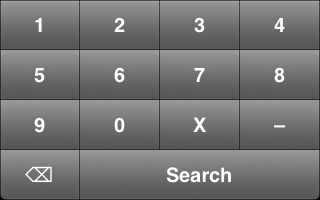
Second, an iOS client that scanned barcodes and accepted DOI numbers from the user and queried the m-biblio web service for results. The references were stored on the phone and could be exported (via email) in Harvard or Chicago bibliographic styles. A third-party library was used for scanning and decoding barcodes, but some development effort was needed to create a decoder for the Telepen barcodes used by the University library. We opted to create a iOS native application (iPhone, iPad, iPod Touch) to take advantage of the native widgets and controls to allow rapid application development with a responsive user interface.
Conclusions and recommendations
The project does demonstrate the potential capabilities of using mobile devices to capture and manage citations and how there is a place for such a tool in the existing study and research workflow of students. The RFID tags used by the library couldn’t be read by NFC-capable devices, but further investigation is needed to look at taking advantage of new RFID library standards. The app could be developed further to provide better management of captured references, allow the export to more formats (including Endnote and Bibtex) and provide a way of capturing DOI numbers through a camera rather than the software keypad on the device.